







写一个对文件进行压缩和解压缩的程序,功能如下:
① 可以对纯英文文档实现压缩和解压;
② 较好的界面程序运行的说明。
介绍哈夫曼:
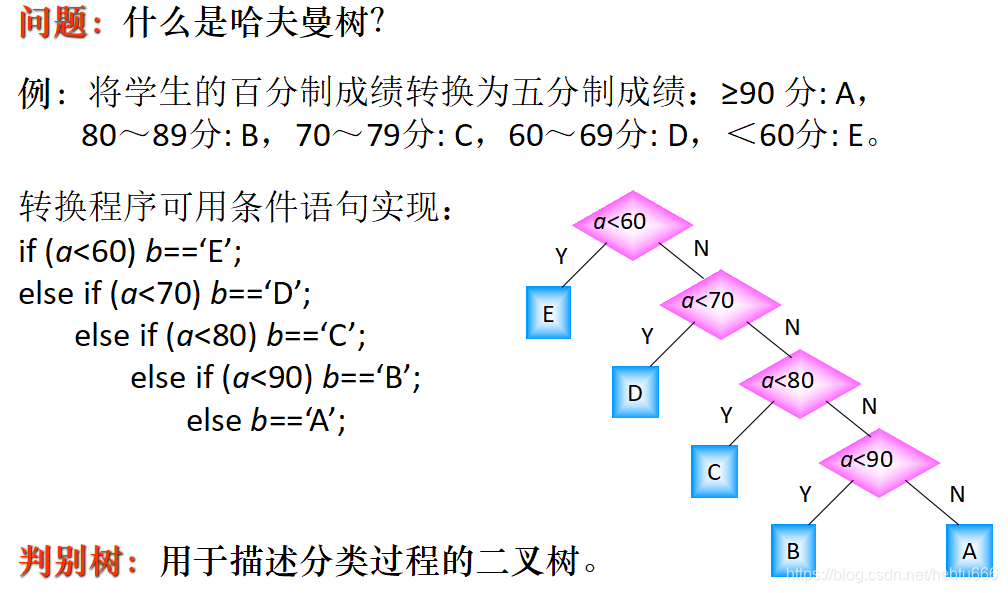
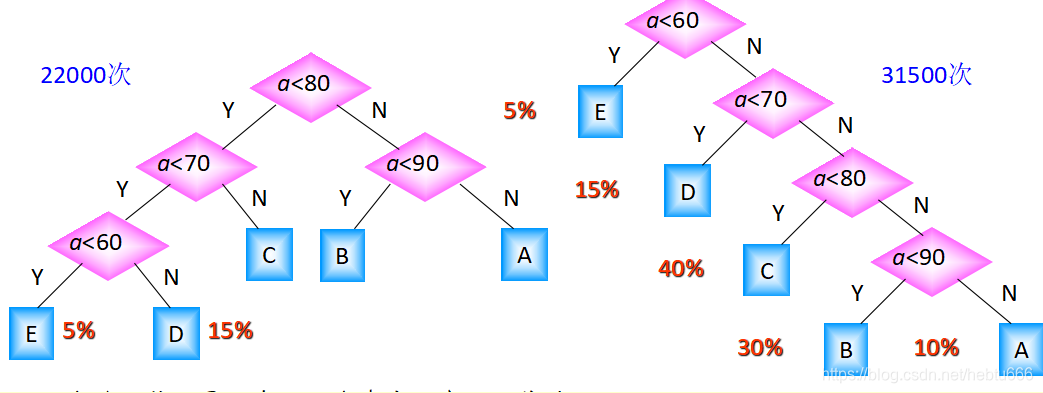
效率最高的判别树即为哈夫曼树
在计算机数据处理中,霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
例如,在英文中,e的出现机率最高,而z的出现概率则最低。当利用霍夫曼编码对一篇英文进行压缩时,e极有可能用一个比特来表示,而z则可能花去25个比特(不是26)。用普通的表示方法时,每个英文字母均占用一个字节,即8个比特。二者相比,e使用了一般编码的1/8的长度,z则使用了3倍多。倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。
霍夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。树的路径长度是从树根到每一结点的路径长度之和,记为WPL=(W1*L1+W2*L2+W3*L3+...+Wn*Ln),N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li(i=1,2,...n)。可以证明霍夫曼树的WPL是最小的。
文件压缩与解压
姓名: 范天祚
1 程序说明
1.1数据结构
哈夫曼树
1.2函数功能说明
printfPercent界面
compress()读取文件内容并加以压缩,将压缩内容写入另一个文档
uncompress()解压缩文件,并将解压后的内容写入新文件
1.3 程序编写的思路及流程
压缩:统计字符出现次数、将节点按出现次数排序、构造哈夫曼树、设置字符编码、读文件字符、按设置好的编码替换字符、写入存储文件
解压:读取文件各参数、转换成二进制码、按码求对应字符、写入存储文件
#define _CRT_SECURE_NO_WARNINGS
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
struct head
{
int b; //字符
long count; //文件中该字符出现的次数
long parent, lch, rch; //make a tree
char bits[256]; //the huffuman code
};
struct head header[512], tmp; //节点树
void printfPercent(int per)
{
int i = 0;
printf("|");
for(i = 0; i < 10; i++)
{
if(i < per/10)
printf(">");
else
printf("-");
}
printf("|已完成%d%%\n",per);
}
//函数:compress()
//作用:读取文件内容并加以压缩
//将压缩内容写入另一个文档
int compress(const char *filename,const char *outputfile)
{
char buf[512];
unsigned char c;
long i, j, m, n, f;
long min1, pt1, flength;
FILE *ifp, *ofp;
int per = 10;
ifp = fopen(filename, "rb"); //打开原始文件
if (ifp == NULL)
{
printf("打开文件失败:%s\n",filename);
return 0; //如果打开失败,则输出错误信息
}
ofp = fopen(outputfile,"wb"); //打开压缩后存储信息的文件
if (ofp == NULL)
{
printf("打开文件失败:%s\n",outputfile);
return 0;
}
flength = 0;
while (!feof(ifp))
{
fread(&c, 1, 1, ifp);
header[c].count ++; //读文件,统计字符出现次数
flength ++; //记录文件的字符总数
}
flength --;
header[c].count --;
for (i = 0; i < 512; i ++) //HUFFMAN算法中初始节点的设置
{
if (header[i].count != 0)
header[i].b = (unsigned char) i;
else
header[i].b = -1;
header[i].parent = -1;
header[i].lch = header[i].rch = -1;
}
for (i = 0; i < 256; i ++) //将节点按出现次数排序
{
for (j = i + 1; j < 256; j ++)
{
if (header[i].count < header[j].count)
{
tmp = header[i];
header[i] = header[j];
header[j] = tmp;
}
}
}
for (i = 0; i < 256; i ++) //统计不同字符的数量
{
if (header[i].count == 0)
break;
}
n = i;
m = 2 * n - 1;
for (i = n; i < m; i ++)
{
min1 = 999999999;
for (j = 0; j < i; j ++)
{
if (header[j].parent != -1) continue;
if (min1 > header[j].count)
{
pt1 = j;
min1 = header[j].count;
continue;
}
}
header[i].count = header[pt1].count;
header[pt1].parent = i;
header[i].lch = pt1;
min1 = 999999999;
for (j = 0; j < i; j ++)
{
if (header[j].parent != -1) continue;
if (min1 > header[j].count)
{
pt1 = j;
min1 = header[j].count;
continue;
}
}
header[i].count += header[pt1].count;
header[i].rch = pt1;
header[pt1].parent = i;
}
for (i = 0; i < n; i ++) //构造HUFFMAN树,设置字符的编码
{
f = i;
header[i].bits[0] = 0;
while (header[f].parent != -1)
{
j = f;
f = header[f].parent;
if (header[f].lch == j)
{
j = strlen(header[i].bits);
memmove(header[i].bits + 1, header[i].bits, j + 1);
header[i].bits[0] = '0';
}
else
{
j = strlen(header[i].bits);
memmove(header[i].bits + 1, header[i].bits, j + 1);
header[i].bits[0] = '1';
}
}
}
//下面的就是读原文件的每一个字符,按照设置好的编码替换文件中的字符
fseek(ifp, 0, SEEK_SET); //将指针定在文件起始位置
fseek(ofp, 8, SEEK_SET); //以8位二进制数为单位进行读取
buf[0] = 0;
f = 0;
pt1 = 8;
printf("读取将要压缩的文件:%s\n",filename);
printf("当前文件有:%d字符\n",flength);
printf("正在压缩\n");
while (!feof(ifp))
{
c = fgetc(ifp);
f ++;
for (i = 0; i < n; i ++)
{
if (c == header[i].b) break;
}
strcat(buf, header[i].bits);
j = strlen(buf);
c = 0;
while (j >= 8) //当剩余字符数量不小于8个时
{
for (i = 0; i < 8; i ++) //按照八位二进制数转化成十进制ASCII码写入文件一次进行压缩
{
if (buf[i] == '1') c = (c << 1) | 1;
else c = c << 1;
}
fwrite(&c, 1, 1, ofp);
pt1 ++;
strcpy(buf, buf + 8);
j = strlen(buf);
}
if(100 * f/flength > per)
{
printfPercent(per);
per += 10;
}
if (f == flength)
break;
}
printfPercent(100);
if (j > 0) //当剩余字符数量少于8个时
{
strcat(buf, "00000000");
for (i = 0; i < 8; i ++)
{
if (buf[i] == '1') c = (c << 1) | 1;
else c = c << 1; //对不足的位数进行补零
}
fwrite(&c, 1, 1, ofp);
pt1 ++;
}
fseek(ofp, 0, SEEK_SET); //将编码信息写入存储文件
fwrite(&flength,1,sizeof(flength),ofp);
fwrite(&pt1, sizeof(long), 1, ofp);
fseek(ofp, pt1, SEEK_SET);
fwrite(&n, sizeof(long), 1, ofp);
for (i = 0; i < n; i ++)
{
tmp = header[i];
fwrite(&(header[i].b), 1, 1, ofp);
pt1++;
c = strlen(header[i].bits);
fwrite(&c, 1, 1, ofp);
pt1++;
j = strlen(header[i].bits);
if (j % 8 != 0) //当位数不满8时,对该数进行补零操作
{
for (f = j % 8; f < 8; f ++)
strcat(header[i].bits, "0");
}
while (header[i].bits[0] != 0)
{
c = 0;
for (j = 0; j < 8; j ++)
{
if (header[i].bits[j] == '1') c = (c << 1) | 1;
else c = c << 1;
}
strcpy(header[i].bits, header[i].bits + 8);
fwrite(&c, 1, 1, ofp); //将所得的编码信息写入文件
pt1++;
}
header[i] = tmp;
}
fclose(ifp);
fclose(ofp); //关闭文件
printf("压缩后文件为:%s\n",outputfile);
printf("压缩后文件有:%d字符\n",pt1 + 4);
return 1; //返回压缩成功信息
}
//函数:uncompress()
//作用:解压缩文件,并将解压后的内容写入新文件
int uncompress(const char *filename,const char *outputfile)
{
char buf[255], bx[255];
unsigned char c;
char out_filename[512];
long i, j, m, n, f, p, l;
long flength;
int per = 10;
int len = 0;
FILE *ifp, *ofp;
char c_name[512] = {0};
ifp = fopen(filename, "rb"); //打开文件
if (ifp == NULL)
{
return 0; //若打开失败,则输出错误信息
}
//读取原文件长
if(outputfile)
strcpy(out_filename,outputfile);
else
strcpy(out_filename,c_name);
ofp = fopen(out_filename, "wb"); //打开文件
if (ofp == NULL)
{
return 0;
}
fseek(ifp,0,SEEK_END);
len = ftell(ifp);
fseek(ifp,0,SEEK_SET);
printf("将要读取解压的文件:%s\n",filename);
printf("当前文件有:%d字符\n",len);
printf("正在解压\n");
fread(&flength, sizeof(long), 1, ifp); //读取原文件长
fread(&f, sizeof(long), 1, ifp);
fseek(ifp, f, SEEK_SET);
fread(&n, sizeof(long), 1, ifp); //读取原文件各参数
for (i = 0; i < n; i ++) //读取压缩文件内容并转换成二进制码
{
fread(&header[i].b, 1, 1, ifp);
fread(&c, 1, 1, ifp);
p = (long) c;
header[i].count = p;
header[i].bits[0] = 0;
if (p % 8 > 0) m = p / 8 + 1;
else m = p / 8;
for (j = 0; j < m; j ++)
{
fread(&c, 1 , 1 , ifp);
f = c;
_itoa(f, buf, 2);
f = strlen(buf);
for (l = 8; l > f; l --)
{
strcat(header[i].bits, "0"); //位数不足,执行补零操作
}
strcat(header[i].bits, buf);
}
header[i].bits[p] = 0;
}
for (i = 0; i < n; i ++)
{
for (j = i + 1; j < n; j ++)
{
if (strlen(header[i].bits) > strlen(header[j].bits))
{
tmp = header[i];
header[i] = header[j];
header[j] = tmp;
}
}
}
p = strlen(header[n-1].bits);
fseek(ifp, 8, SEEK_SET);
m = 0;
bx[0] = 0;
while (1)
{
while (strlen(bx) < (unsigned int)p)
{
fread(&c, 1, 1, ifp);
f = c;
_itoa(f, buf, 2);
f = strlen(buf);
for (l = 8; l > f; l --)
{
strcat(bx, "0");
}
strcat(bx, buf);
}
for (i = 0; i < n; i ++)
{
if (memcmp(header[i].bits, bx, header[i].count) == 0) break;
}
strcpy(bx, bx + header[i].count);
c = header[i].b;
fwrite(&c, 1, 1, ofp);
m ++;
if(100 * m/flength > per)
{
printfPercent(per);
per += 10;
}
if (m == flength) break;
}
printfPercent(100);
fclose(ifp);
fclose(ofp);
printf("解压后文件为:%s\n",out_filename);
printf("解压后文件有:%d字符\n",flength);
return 1; //输出成功信息
}
int main(int argc,const char *argv[])
{
memset(&header,0,sizeof(header));
memset(&tmp,0,sizeof(tmp));
compress("测试文档.txt","测试文档.txt.zip");
uncompress("测试文档.txt.zip","测试文档.txt 解压后.txt");
system("pause");
return 0;
}
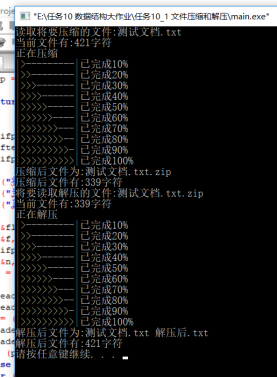
2 功能展示
2.1 控制台显示
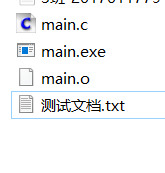
2.2 文件效果
开始时只有一个文件《测试文档.txt》:
打开《测试文档.txt》
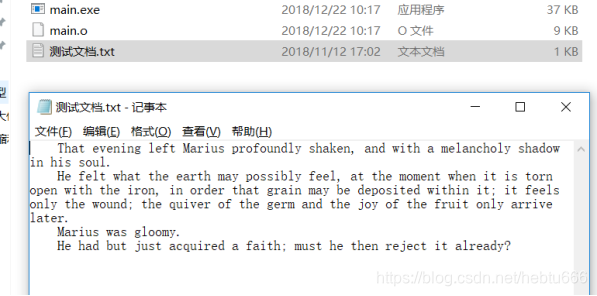
《测试文档.txt》文件大小:
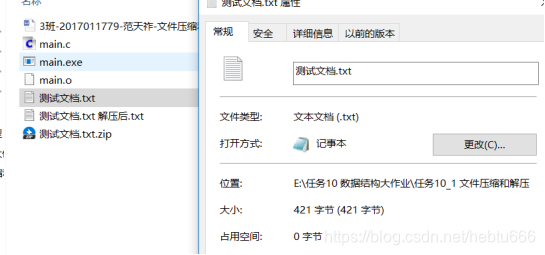
程序运行结束后多了两个文件:
以文本形式打开压缩二进制文件《测试文档.txt.zip》:

《测试文档.txt.zip》文件属性:

















 769
769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











